Archive for the ‘Clicky’ Category
Heatmap updates: Longer storage, better scaling, and new filters
We just pushed some updates to heatmaps today.
First, we’ve extended the storage time to 6 months, up from 3. When we released these about 15 months ago, we were worried that they would take up too much space if we kept them around for too long, so we were limiting to 3 months of data. It took a while before lots of people were using them, so we couldn’t analyze the impact on storage space fairly reliably until recently. Good news, they take up less space than we had anticipated because we made some good decisions on the design side of things. Of course, the data older than 3 months from right now has already been purged, so you don’t have 6 months now. But 3 months from now, you will.
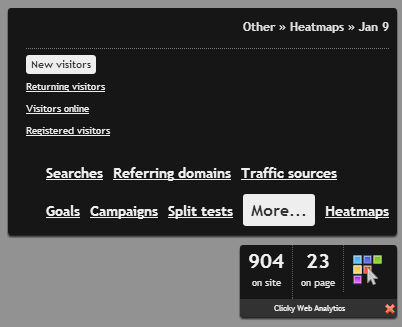
Second, we added a few new filter options when using heatmaps via the on site analytics widget. The new filters are under the More… menu, as shown below. These new filters allow you to view heatmaps for a page for just new visitors, returning visitors, visitors online now, or registered visitors. Registered means they have a username custom data field attached to them.
We’ll probably add a few other filters as we think of them. What would you like to see here? One thing we considered was some kind of engagement filter, e.g. only visitors who bounced or only visitors who did NOT bounce. However, if you think about it, almost everyone who bounces would not have clicked anything on your site, so it wouldn’t really tell you much.
Last, we changed the scaling of the heatmaps. The problem was that for pages with lots of clicks, there would generally be a few extremely hot areas, e.g. in the navigation bar, and they would be so much hotter than the rest of the page, the other clicks would not even be visible. We’ve changed it so the scale of hotness now only goes from 1 to 10, rather than 1 to whatever it would happen to be as stored in the database.
Here is an example of a heatmap for our homepage using the old method, for all clicks:
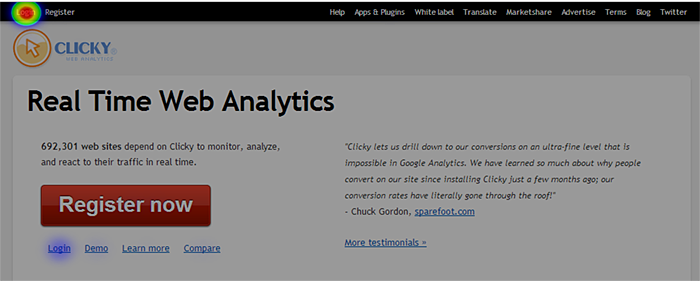
Most visitors coming to our site are already customers, so the two login links are going to be the most clicked items, by about a thousand miles. Of course, there are plenty of other clicks on this page (e.g. new people signing up are going to click the big ass register button), but we can’t see them unless we apply some filters first, such as only showing visitors who completed our new user goal. It would be real nice to be able to see ALL the clicks on this page though, wouldn’t it?
So here’s what the new scaling method does to the exact same pool of data in the last screenshot, most of which was completely invisible:
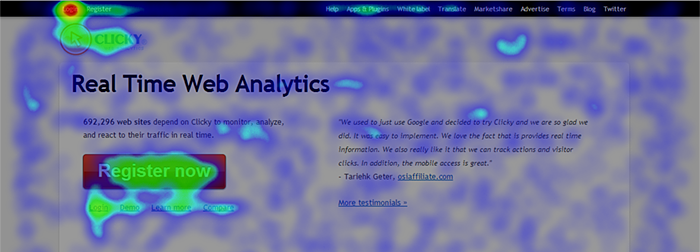
It’s certainly noisier but the hot areas still stand out, and yet you can see every single click on the page, because the range from min to max is so much smaller.
Let us know what you think!
Twitter direct messages
Four and a half years ago we released several Twitter features, one of those being to receive alerts via direct message on Twitter. This has been an awesome feature and we have used it ourselves since day one, to be notified of certain goals happening on our site, such as a new paying customer. Earlier this year we released our uptime monitoring feature, and we added Twitter direct message alerts there also.
So we are sad to say that today, these features have been removed, and it’s unlikely they will ever come back.
Sometime in mid-October, Twitter added some pretty strict throttling. We never saw any news about this, but within a few days we started getting tweets and emails about Twitter alerts no longer working. A bit of research led us to this page on Twitter’s web site, which says that all accounts are now limited to sending 250 direct messages per day, whether via the API or not.
We send many many thousands of direct messages a day, hence this feature is now severely broken. We blow through 250 direct messages by 1 AM most days. So unless Twitter revises this limit to something much higher, this feature is permanently dead.
Many other services have probably been affected by this throttle. It just really bothers me how much Twitter keeps slapping third party developers in the face, the very people who helped build Twitter into what it is today. One thing I know, we will never add another Twitter feature to Clicky, ever. Our Twitter analytics feature still works, thankfully. For now, anyways…
Twitter direct messages = :(
Four and a half years ago we released several Twitter features, one of those being to receive alerts via direct message on Twitter. This has been an awesome feature and we have used it ourselves since day one, to be notified of certain goals happening on our site, such as a new paying customer. Earlier this year we released our uptime monitoring feature, and we added Twitter direct message alerts there also.
So we are sad to say that today, these features have been removed, and it’s unlikely they will ever come back.
Sometime in mid-October, Twitter added some pretty strict throttling. We never saw any news about this, but within a few days we started getting tweets and emails about Twitter alerts no longer working. A bit of research led us to this page on Twitter’s web site, which says that all accounts are now limited to sending 250 direct messages per day, whether via the API or not.
We send many many thousands of direct messages a day, hence this feature is now severely broken. We blow through 250 direct messages by 1 AM most days. So unless Twitter revises this limit to something much higher, this feature is permanently dead.
Many other services have probably been affected by this throttle. It just really bothers me how much Twitter keeps slapping third party developers in the face, the very people who helped build Twitter into what it is today. One thing I know, we will never add another Twitter feature to Clicky, ever. Our Twitter analytics feature still works, thankfully. For now, anyways…
Sticky data: Custom data, referrers, and campaigns saved in cookies
[Do not panic. You do not need to update your tracking code.]
We’ve just pushed a major update to our tracking code so it works a bit more like one aspect of Google Analytics now, that being that some additional data is saved in first party cookies (set with Javsascript) for visitors to your site. This data being referrers, dynamic (UTM) campaign variables, and custom data set with clicky_custom.visitor (renamed from clicky_custom.session – don’t worry, the old name will still work indefinitely).
We’re calling this sticky data and the point of it is two fold. First, for referrers and dynamic campaigns, this will better attribute how your visitors originally arrived at your site, as they visit in the future. In other words, if they find your site via a link or search, all future visits to your site where they go directly to your site instead of through a link, this original referrer (and/or campaign) will be attached to these new sessions. This will be particularly useful for those of you who have setup goal funnels using referrers or campaigns. These cookies are set for 90 days. Google does 180, which we think is a bit too long, so we’re doing 90 instead.
(Note: This does not work for static (pre-defined) campaigns that you create in Clicky’s interface. It only works with the dynamic ones created with e.g. utm_campaign etc variables).
Second, if you set custom visitor data, we’ve thought for a while now how great it would be if that data stuck across visits. For example if someone logs in and you attach their username to their session, that’s great – everytime they login that is. But what about when they visit your site in the future but don’t login? Well, now that we save this data in a cookie, their username will still get attached to their session so you’ll still know who they are. These cookies are set indefinitely, more or less.
A lot of you use custom visitor data to attach things that are very session specific though, such as shopping card IDs, that kind of thing. With this in mind, there are only 3 specific keys we’ll save by default for custom visitor data. Those keys are username, name, and email. Of course, if you have others you want to save in cookies, you can customize it with the new visitor_keys_cookie option. Click that link to learn more.
We think the vast majority of you will like this new sticky data. However, if for some reason you don’t, we created another new clicky_custom option as well, sticky_data_disable. Setting this option will disable this data being saved to or read from cookies, without having to fully disable cookies. And of course, if you have fully disabled cookies, this data will never get saved in the first place.
Originally we wanted to add support for parsing GA’s __utmz cookies, which is what GA uses to store campaign and referrer data for 6 months. The cookie format is fairly straight forward but upon investigating our own GA cookies we saw a lot of inconsistency across all the sites that it had been set for. So we’re going to hold off on that for now.
Our privacy section on cookies has been updated to reflect these updates.
Enjoy!
New features: Site domains, and ignore pages by URL
We just pushed two new features today.
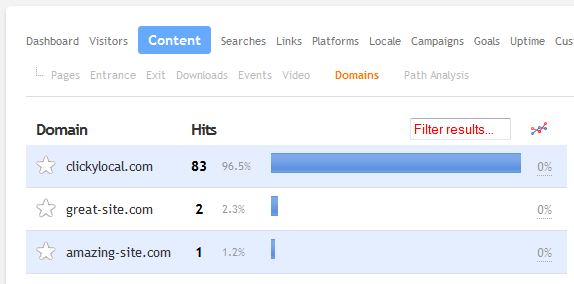
The first is site domains, where we break down the traffic on your site by the domain name each page view was on. This will only be interesting if your site has multiple sub-domains, or you are tracking more than one root domain under a single site ID – but we know that there are a lot of you out there that this will apply to, as it has been requested a number of times.
This new report is under Content -> Domains. Note that we are only logging the domain name for each page view, to give you a general idea of where your traffic is going. You can’t filter other reports by this data.
A commonly requested and related feature is breaking down traffic by directory. We will be adding this in the future.
The second feature is the ability to ignore page views based on their URL. This has been requested by many customers!
This can be setup in your site preferences, as explained in this new knowledge base article. You can enter in one or more patterns to match and all page views that match those patterns will be ignored. Side effects: 1) If a visitor only views pages that match your filters, the visitor will not be logged at all. 2) If a visitor lands on one of these filtered pages but then views other pages, some data only available on their first page view, such as referrer, will not be available.
The help document linked above also explains how to set these up. We support wildcards but only on the end of a pattern, for example. Read it for full details.
We get requests to ignore traffic based on other things too, such as country, referrer, and organization. Some or all of these will likely be added in a future update, and when we do that we’ll probably just create an entirely new preferences section just for setting up things you don’t want to log, instead of piling more options onto the main site preferences page.
The best return on investment we’ve made
Clicky is almost 7 years old and we’ve always been a very small team. We’ve handled all of the email ourselves since the beginning, using gmail, which we like. I doubt there’s a single human being that enjoys doing tech support, but it’s critical to customer satisfaction. It’s also one of those things that quickly spirals out of control if you’re not on top of it every single day, and it takes away precious time from what we really want do (write code).
At our peak we were getting almost 50 emails a day. Now we’re down to about 20. How did we do that? Black magic? No. What we did was build a knowledge base with hundreds of topics (over 300 and counting), including many guides/howto’s and tons of the most common problems people have.
Aside from hoping to get less emails, we really just wanted thorough guides and articles with screenshots to make things as easy as possible to understand for new and old customers alike, instead of having to type the same email 10 times a day when someone asks where’s my tracking code?. When a customer reads an article we link them to, they’re now aware of the knowledge base if they weren’t already, and will hopefully turn there first in the future when in need of help.
We released this silently back in March and the effect was immediately noticeable. Email volume dropped in half almost overnight, and has slowly declined a bit more since then as more people become aware of it. It also helps that the contact page is now only available as a link from the knowledge base page. We’re not trying to hide our contact info like some companies do, rather we just want people to see the knowledge base first.
It was a solid two weeks of work coming up with a list of articles to write, categorizing them into a tree, cross-linking them, and writing them all out with screenshots etc. It was an extremely boring and repetitive two weeks, but let me tell you: it was worth every dreadful second.
It’s been especially insightful using our heatmap tracking to see what items people are most interested in on each page, and how many people are exploring the knowledge base rather than clicking the link to contact us.
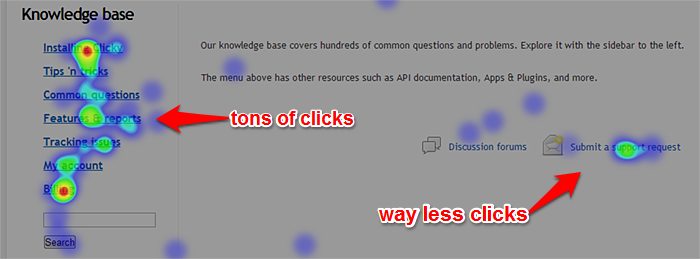
The only thing missing it from it was a search form. That’s part of the reason for today’s post, to announce that we finally added a search form to the page. The reason it didn’t have one before was because I was going to write a custom search with customized weighting and things like that. But out of the blue yesterday, it was suggested to me that I just use Google’s search for it. Not a bad idea, I thought. At the very least it’s better than a kick in the pants. It only took about 5 minutes of work to do that, which was great, but also made me sad I didn’t think of this before.
Anyways, when you do a search now, it redirects you to google.com with site:clicky.com inurl:/help/faq/ appended onto the end of your search, so the results are only from our knowledge base. Yeah, I could do their embedded search thing, but I don’t like that.
I was not planning to leave it as a Google search forever, but then I thought about the thousands of man-years of experience that Google has building a search engine, and frankly they’re pretty dang good at it. With things like automatic spelling correction, accounting for word varations, and semantic analysis, it works really well. I tested tons of searches (to the point of getting banned because they thought I was a robot) and everything I threw at it worked great, including the order of the search results. I don’t like that it takes people off our site, but for now I don’t see a better option.
The real point of this post is just to say that building a knowledge base has been the best return on investment we ever made. We easily save 1-2 hours every single day because our email load has dropped so much, and I imagine with the new search functionality, it will drop even more.
Other amazing returns for us have been virtualizing all of our servers, which we wrapped up last year, and automated deployment to all production servers when we push new code to our main web server with Git. These save us huge amounts of time, and time is money my friends. Virtualization was probably the biggest project we’ve ever done, taking about a full year, so the investment was gigantic. But everytime I deploy a new server with a single command, I am one happy panda.
What’s the best ROI your company has had?
CDN fault-tolerance
This is a post for web developers.
What do you do when your CDN fails to serve a resource to a visitor?
For a year or two, we’ve had a message at the top of our site that more or less said If you’re seeing this message, our style sheet has failed to load. Try clearing your cache, wait a few minutes and try again, etc. Of course you wouldn’t see this message if it our stylesheet had loaded, because our stylesheet had a rule to hide it.
That’s a reasonable first step. At least we’re communicating that we know something is wrong. But we still get customers emailing in a few times a month and the CDN just wouldn’t work no matter what they tried. Maybe a CDN server in their location was having an outage, even though traffic should get routed around that, failures still happen. Maybe the customer’s DNS is failing. Lots of possibilities, and almost always impossible to track down because eventually, within a day or two at the most, it would always start working for them again.
Clicky isn’t usable without CSS (I know, I know…), and minorly broken without javascript (e.g. graphs). This kind of problem is just annoying, so I finally resolved to fix it. As any page on our site is loading, we use a few inline javascript tests to see if our master javascript file and master CSS file have loaded. If we detect a failure for either of those, then we try to load the resource a second time, directly from our web server. The code looks like this:

As you can see, this goes right at the top of the BODY tag. There are two reasons we need to wait until the BODY tag. First, we are creating an element to test its visibility immediately. We have to wait until BODY to do that. Second, if there is a CSS failure, we need to inject a new CSS element into the HEAD tag, but we can’t do that until we are closed out of the HEAD tag. So, we wait until BODY.
Here’s how the code works.
First, we create an empty element, #cdnfailtest, which we’ll be testing the visibility of. Then we bust into javascript for the testing.
We want to use jQuery to test if this faux element is actually visible (because jQuery makes that very simple), so before doing that, we check if our javascript file has loaded by testing for window.jQuery. If that test fails, then our minified javascript wasn’t loaded, so we need to load it from the web server. Unfortunately, we have no choice but to use document.write() in order to guarantee the script file is loaded immediately.
I did notice during testing however, even with document.write(), the javascript file wasn’t always immediately available. It was a bit random on every refresh whether or not it worked. So we wrap the rest of the code within a setTimeout() call to delay it slightly (500 milliseconds).
After the 500 milliseconds, we start the CSS visibility test. We use jQuery to find the element #cdnfailtest and see if it’s visible. (If jQuery still isn’t loaded, we assume something is wrong and force load the CSS from the web server anyways, just to be safe). If it is visible, that means the CSS did not load, because otherwise its rules would hide the element.
This is the part where we need the HEAD element to be already fully declared, so we can attach and inject the CSS file into it. That’s what the rest of the code does. Since CSS is fine to load asynchronous, we use the more modern method of adding it to the DOM (which we can’t use for the javascript file, because even when async is not specified, it still seems to load it like that – e.g. parsing continues while that file is loaded in the background). So the page may still look funny for a moment, but that should only be the case for a second or two.
Anyways, this is our solution to this problem. If you have had to come up with your own solution, we’d be interested to see how yours works.
1 minute uptime monitoring! And more new custom upgrade options.
We just launched a revamped upgrade page with some highly requested feature customization options.
- 1 minute uptime monitoring intervals – When we launched uptime monitoring in beta back in January, we said that 1 minute uptime would be coming soon. Ha. Anyways, we still haven’t launched Monitage as its own standalone product yet, so we still consider it a beta feature for the moment, but we’ve had a lot of requests for 1 minute monitoring so now you can choose that interval if desired.
There’s also the option to increase the number of monitors you can have per site, up to 10 (default is 3).
- Higher heatmap sampling – Heatmaps by default only sample 50% of visitors, minus mobile visitors (we’ll eventually log them, once we get to test things them more). Now there are more options for this, all the way up to 100% (again, minus mobile visitors).
- API throttling – Back in February we had to start throttling the analytics API, as some customers’ heavy usage was impacting some of our database servers’ ability to keep up with real time. This only impacted a couple of specific data types though: visitors-list, actions-list and segmentation.
There are two aspects to throttling. One is that we only allow one request per IP address per site ID at a time. The other is that these types of requests are limited to 1000 results and a max date range of 7 days.
The option to remove API throttling that we are offering now is for the first throttle only, that is, you will now be allowed to send unlimited requests per IP address per site ID. However, the date range and max result size of 1000 will still be in effect. We’ve analyzed the data and we just can’t offer this without impacting a large number of customers.
Here’s what the new upgrade page looks like:
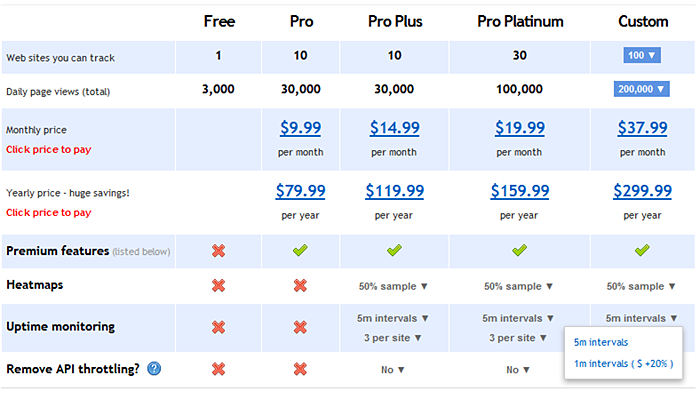
Each customization you choose increases the price by a certain percentage, such as 10%. They don’t compound though, meaning if you choose two upgrades that each increase the price, they are each calculated based on the core price of the non-customized plan.
If you’re ready to take the plunge, you can upgrade here.
Local search now supports ‘pretty’ searches and multiple parameters
By popular demand, local searches now support multiple parameters, as well as path based pretty searches. You can mix the two types as well. To use multiple of either one, just separate with commas.
For path based searches, what you want to enter is everything that goes between the domain name and the search term. For example, if someone searches for apples on your web site and they end up here:
http://yourwebsite.com/search/apples
Then you would enter in /search/ into the box. Without quotes of course.
For good measure, here is an example of a comma separated list of both types, pretending your site has both q and s as search parameters, and also does path based search with the search term appearing after /search/, as shown above:
/search/,q,s
Tracking tel: URLs, custom heatmap objects, and other tracking code updates
Note 1: DO NOT PANIC. You don’t need to change anything with the code installed on your site. We’ve simply made some changes to the way the code works, adding a couple of features and fixing a few bugs.
Note 2: Other than the tel: tracking, most of this only applies to advanced users.
New features
- Tracking tel: URLs – This has been requested here and there over the years, but as Skype et al become more ubiquitous, these URLs are on more and more pages. So we just added support for automatically tracking them. Like mailto: links, these will show up in your outbound link report. You don’t need to do jack diddly, it should just work.
- Custom heatmap object tracking – Our heatmap code by default listens for clicks that bubble up to the document.body element. The default for all events is to bubble up, but there are plenty of events that don’t do this, which means those clicks weren’t being captured. We ourselves have been affected by this too, mainly by our Javascript menus.
So now there is a new clicky_custom property, heatmap_objects. With this you can specify custom elements, by tag name, ID, or class. It can be a string if you just need to specify one thing (most likely), or it can be an array of strings if you need to specify more than one. Using this we can track clicks on these elements. Which reminds me, I forgot to update our own Javascript code to track our menus! Mental note.
You should ONLY use this for events that don’t bubble up, or you will experience oddness.
- clicky.goal() changes – This likely does not affect you but if you use the clicky.goal() javascript method at all, you may want to read on.
When we released heatmaps, we added a new event queue system for logging some items in batches: heatmap data, javascript events, and javascript goals. The reasoning behind this change was to reduce bandwidth for heatmaps, and increase accuracy for events and goals. The accuracy part being that if you sent a hit to clicky.log() or clicky.goal() when someone clicked on a link that would result in a new page being loaded, chances were good that it would not be logged because the page would be unloaded from the browser before the logging request went through.
So the queue system was made to store events and goals in a cookie, which is then processed every 5 seconds. So if the person is just sitting on the same page still, the queue will be processed shortly and send that event/goal to us. But if instead a new page is loaded, the cookie is still there holding the event/goal that wasn’t logged on the last page, and can be processed immediately on the new page view (which we do before processing the new page view itself, to ensure things are in the correct chronological order).
ANYWAYS… there were some customers who were using clicky.goal to log goals when visitors were leaving their site. The queue would intercept these goals though, resulting in a snowball’s chance in hell of the goal ever being logged.
SO… we added a new parameter to clicky.goal() called no_queue, which will tell our code to skip the queue and just log the goal immediately. Check the docs for more.
This doesn’t affect many of you, but if it does, the back story I’ve written above is probably worth a read.
- New method to check if a site ID has been init()’d – for customers using multiple tracking codes on a single site/page. This was a specific request from one customer, but we realized our code itself wasn’t even doing this sanity check, so if you had the SAME code on your site multiple times, there were some minor bugs that resulted from this.
If for some reason you think this applies to you, the new method is clicky.site_id_exists(123), which returns true or false indicating whether this site ID has been passed through the clicky.init() function yet. Note: 123 is an example site ID. Use a real one.
Bug fixes for sites using multiple tracking codes
In addition to the last item above about loading the same site ID multiple times resulting in oddities (and which is now fixed), we’ve made another change to the way the init process works.
There are a number of things that happen when a site ID is init()’d, but it turns out most of those things only needed to happen once, even if you had multiple site IDs on a aingle page. However, our code was executing this entire init process for every site ID on a page, which resulted in bugs such as:
- clicky_custom.goals and clicky_custom.split only working with the first site ID that was init()’d.
- The automatic pause that we inject for tracking downloads and outbound links was being called once for every site ID, rather than once per click (which is all that’s needed)
- When loading heatmaps by clicking the heatmap link from clicky.com, the heatmap would sometimes load twice (making it extra dark).
There were a few other much more minor bugs, but those were the ones that were really irritating. So now what happens is we split the setup procedure into a different method, and wait 100 milliseconds before calling it (just once), giving a chance for all site IDs to be passed into the init process first. And the actual init() method now just puts each site ID into an array which we loop through when any request to log data is called.
Coming soon
Been requested a number of times and something we will definitely add in the coming months. That being when you set custom visitor data with clicky_custom.session (or utm_custom), we will store this data in a cookie so the data will be applied to all future visits by this person, so even if they’re not logged in, they’ll still be tagged as they were last logged in / tagged visit.
We’ll probably only do this with a few specific keys though, since people use clicky_custom.session for all kinds of crazy purposes, many of which can be session specific. But we’ll probably do something like, only do it for keys like username, name, email, and a few others.
Just something to watch out for. We think this will be a nice addition when we add it.
Recent Comments